Actualmente son muchas las empresas que utilizan Pentaho Data Integration (PDI) para tareas de integración de datos, obteniendo los beneficios que la herramienta brinda para obtener, transformar y distribuir datos. Sin embargo, en su arquitectura por defecto, no resulta natural crear y ejecutar modelos de inteligencia artificial, como etapas que agregan valor al flujo de datos con el cual se está trabajando.
Afortunadamente, es posible optimizar una arquitectura basada en Pentaho, de forma tal, que se logra combinar las excelentes funcionalidades que brinda PDI para la manipulación de datos, con la posibilidad de crear y ejecutar algoritmos de inteligencia artificial, tales como optimización, predicción y prescripción, totalmente integrados al flujo de datos de PDI.
En Adagio trabajamos con analítica de datos abarcando todo el espectro del ciclo que incluye analítica descriptiva, predictiva y prescriptiva. Hemos desarrollado proyectos en donde construimos modelos predictivos con análisis estadísticos, mediante soluciones de optimización y machine learning (aprendizaje automático).
Etapas de desarrollo de procesos de aprendizaje automático
El desarrollo de procesos de aprendizaje automático se ejecuta en etapas según se representa en el siguiente diagrama:

En el mismo se muestran las distintas fases del proceso de machine learning y cómo interaccionan entre ellas. Las distintas etapas se pueden desarrollar en diversas herramientas y lenguajes de programación.
Para la etapa de elección y/o construcción del modelo, existen múltiples librerías pre-desarrolladas que implementan algoritmos complejos. Mediante su re-utilización se reduce la complejidad y los tiempos requeridos para el desarrollo de procesos de aprendizaje automático.
En la actualidad, los lenguajes de programación preferidos, y a su vez más utilizados en la industria para el desarrollo de procesos de aprendizaje automático son: en primer lugar “Python”, seguido por “R”, y en un distante tercer lugar “Java”.
Por otra parte, las tareas de obtención y preparación de datos, son de igual importancia que la definición de un modelo de aprendizaje óptimo, ya que si este no se alimenta con los suficientes datos, organizados y con la calidad requerida, los resultados obtenidos no serán de valor. Esta tarea habitualmente insume la mayoría de la dedicación en el desarrollo de un proceso de aprendizaje automático.
Según el artículo publicado por Hitachi, los científicos de datos emplean la mayor parte de su tiempo en tareas de obtención y preparación de datos, tareas que a su vez, son las que menos disfrutan ejecutar.
Una propuesta de arquitectura con soporte para el desarrollo de procesos de aprendizaje automático debe cumplir con las siguientes características:
- Brindar herramientas que faciliten las tareas de obtención y preparación de datos.
- Soportar el uso de librerías y algoritmos existentes en los lenguajes de programación más populares para el desarrollo de este tipo de procesos (Python y R).
- Integración con herramientas utilizadas por los científicos de datos para modelado y exploración de los resultados obtenidos (Notebooks y/o herramientas para exploración de datos).
Propuesta de Arquitectura
La herramienta de integración PDI dispone de características que posibilitan y facilitan las tareas de obtención y preparación de datos. Es una herramienta diseñada específicamente para realizar ese tipo de tareas. Sin embargo, de forma nativa, soporta solamente la ejecución de librerías desarrolladas en Java.
A continuación se presenta una propuesta de arquitectura que soluciona la limitante del uso exclusivo de Java, y posibilita la integración con herramientas externas, mediante el estándar JDBC. En la misma se expanden las características de PDI Community Edition, versión 8.2, mediante plugins compatibles.
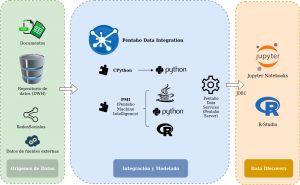
Las funcionalidades nativas de PDI soportan la integración de diversas fuentes de datos, tanto estructuradas, como sin estructurar, brindando de esta forma un completo abanico de posibilidades, en cuanto a los orígenes de datos soportados.
Mediante los plugins “CPython” y “Pentaho Machine Intelligence» , se expanden las capacidades de Pentaho Data Integration, posibilitando con el primero la ejecución de scripts desarrollados en Python, y con el segundo la ejecución de distintos algoritmos de aprendizaje automático, utilizando como plataforma de ejecución Weka, Python, R, o Spark ML Lib. PMI brinda muchos de los algoritmos más utilizados para tareas de inteligencia artificial, siendo posible además, expandir sus funcionalidades mediante nuestros propios algoritmos.
Estos son algunos de los algoritmos incluidos actualmente:
- PM Decision Tree Classifier
- PMI Decision Tree Regressor
- PMI Deep learning network
- PMI Extreme Boosting Classifier
- PMI Extreme Boosting Regressor
- PMI Flow Executor
- PMI Forecasting
- PMI Gradient Boosted Trees
- PMI Linear Regression
Ambos plugins están disponibles en el Marketplace accesible desde PDI para instalación o descarga. Considerar previo a la instalación cumplir con los siguientes requisitos:
- Instalación de Python
- Instalación de los siguientes paquetes de Python:
- python-pandas
- python-scipy
- python-sklearn
- python-matplotlib
- python-numpy
- Instalación de R (requerido solamente para PMI en caso de querer ejecutar utilizando dicha plataforma)
Considerando la instalación de ambos plugins, es posible desarrollar mediante la aplicación de escritorio PDI transformaciones en las que se recuperan, integran y preparan datos de múltiples orígenes, utilizando diversas funcionalidades que facilitan dichas tareas.
El flujo de datos generado se puede someter a pasos que ejecutan distintos algoritmos (o programas completos) de aprendizaje automático, manteniendo los resultados de ejecución de los mismos en el flujo de datos, lo que posibilita que se pueda seguir trabajando sobre los mismos, ya sea para ejecutar otros algoritmos, o realizar tareas de transformación sobre los datos, previo a su salida.
La salida de datos se puede dirigir a un archivo, base de datos, o publicar como un servicio de datos. Esta última alternativa resulta particularmente interesante, ya que mediante esta estrategia se obtiene lo equivalente al concepto de “virtualización de datos”, posibilitando acceder a datos de múltiples fuentes, integrados, transformados, sobre los que se agrega a su vez inteligencia artificial, al vuelo y bajo demanda de uso.
En Pentaho Data Integration es posible definir una salida de datos como un servicio de forma nativa, mediante integración con Pentaho Server, creando un origen de datos en el mismo, desde PDI. A dicho origen de datos se puede acceder de forma mediante conectores JDBC, desde herramientas externas utilizadas por los científicos de datos, tales como Jupyter Notebooks o R-Studio.
Las características descriptas anteriormente, en conjunto, contemplan los objetivos deseables en una arquitectura que posibilita, y brinda facilidades para el desarrollo de procesos de inteligencia artificial.
Ejemplo de armado de un modelo predictivo de Inteligencia Artificial (IA) utilizando la base de datos del Titanic
A continuación presentamos un ejemplo, a modo de caso de estudio, de armado de un modelo predictivo con Pentaho. El mismo se centra en mostrar, de manera simplificada, el aspecto crítico de la arquitectura propuesta incorporando la creación y ejecución de algoritmos de aprendizaje automático en Pentaho PDI.
Utilizando la lista de pasajeros del Titanic, y sus características, se establece como objetivo, utilizar una muestra de la misma para elaborar un modelo capaz de predecir para el restante de los datos, si un pasajero sobrevive o no.
Las variables seleccionadas para contemplar en el armado del modelo son las siguientes:
- sexo
- edad
- si viajaba con familiares
- tipo de boleto
- cuánto pagó por el boleto
Utilizando uno de los pasos disponibles en PMI, creamos un modelo de decisión basado en un árbol de clasificación:

Una vez ejecutada la transformación, el modelo está creado y listo para ser utilizado.
En una nueva transformación, se obtienen los datos restantes (para los cuales queremos predecir si cada pasajero sobrevive o no), y se realizan diversas transformaciones sobre los mismos, con la finalidad de prepararlos de la mejor manera, previo a someterlos al modelo predictivo, maximizando de esta forma las probabilidades de éxito.

Observemos que luego de evaluados los datos por el modelo, en la misma transformación, se obtienen datos de una fuente distinta, que contienen los resultados reales. Mediante la integración de ambos flujos de datos, fácilmente logramos evaluar los resultados obtenidos por la predicción, estableciendo que se obtuvo un porcentaje de acierto superior al 97%.
La etapa de preparación y curado de los datos es la que habitualmente insume el mayor esfuerzo de desarrollo en un proceso de aprendizaje automático Sin embargo, este tipo de tareas se realiza de forma intuitiva con las funcionalidades propias de PDI.
Esta herramienta además de facilitar el proceso de captura, limpieza y almacenamiento de datos utilizando un formato uniforme y consistente, permite procesar e integrar múltiples flujos de datos convirtiéndose en tarea sencilla validar los resultados.
Este tipo de arquitectura de datos integra, combina, convierte y transforma datos de cualquier origen (fuente) en información útil que permite optimizar operaciones reduciendo el tiempo y la complejidad.